
Using the text_analysis function
Before using the Tokens&Lemmas function, we will clean the text a little bit; let’s see how to do it:

Figure 5.26: Tokens&Lemmas expander
Before using the text_analysis function we just discussed, we will clean the text with neattext. First of all, we will remove stopwords from it, then we will remove the punctuation, and finally, we will remove special characters such as “@”, “#”, and so on.
We will pass this cleaned text to text_analyzer and then print the result on the screen.
Please note that, since the text_analyzer function returns a dictionary – or better, a list of dictionaries – we are printing it in the JSON format (st.json(tandl)); this is the result:
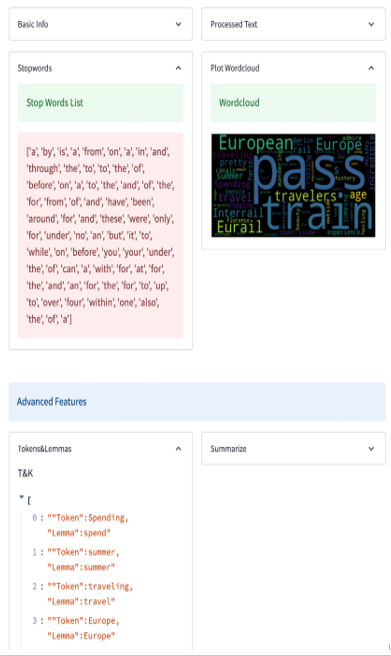
Figure 5.27: Tokens&Lemmas on the screen
To make it very clear, tokens are the words of our text after we clean it, while lemmas are something called the normal shape of the words; for example, we can see that the word spending has spend as a lemma, the token traveling has travel as a lemma, and so on.
Finally, to test that everything works properly, we can copy some text from the web – for example, an extract from some article from the CNN website – and put it in our web application. This is the result in the case of an article about traveling and journeys:
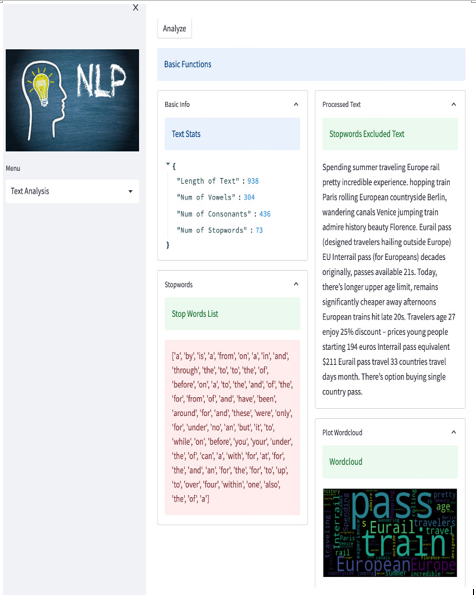
Figure 5.28: Text Analysis test
The result is quite impressive; please consider that by using only Python, Streamlit, and some libraries, we’ve already got a very good-looking, working web application that can be used directly online. All we need is a browser!
If possible, try to use the application from a device – for example, a tablet or smartphone – that is on the same (Wi-Fi) network as the computer from which you are coding. This is the great point of these web applications: immediately accessible from everywhere! We write code once and can use it from everywhere, with no need to install locally, manage patches, manage new versions, and so on. Everything stays in one place and it’s accessed by a web browser. In case of changes or new versions, we only need to update the code server-side, meaning no pain for users. Smooth, clean, and easy!
As usual, here are the screenshots of the code produced up to now:
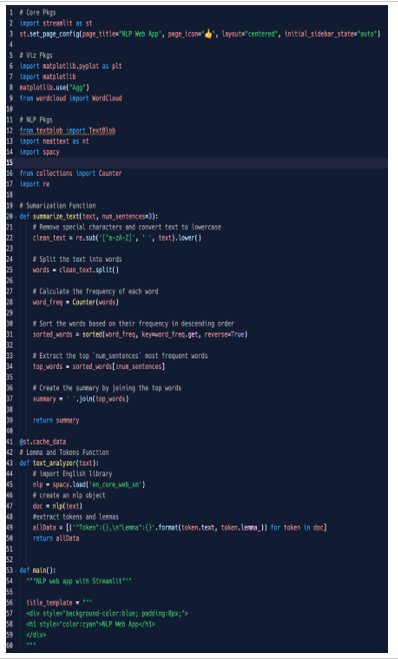
Figure 5.29: Code – part 1
In part 1, we imported the packages, set the page configuration, and defined the “summarize_text” and “text_analyzer” functions.
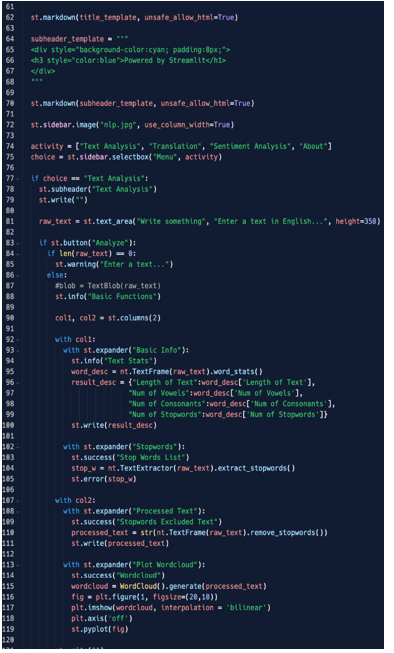
Figure 5.30: Code – part 2
In part 2, we wrote the “main” function that visualizes the main title of the application, the menu in the sidebar that uses an IF clause to make the menu’s voices selection possible, and used some interesting widgets such as columns and expanders.
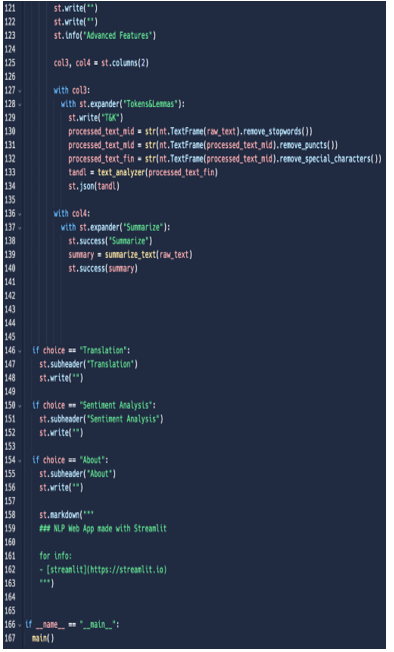
Figure 5.31: Code – part 3
In part 3, we completed the “main” function, then created placeholders for the Translation and Sentiment Analysis features, and finally, created a beautiful About section, leveraging simple markdown.
Let’s underline once again how powerful Streamlit can be, since with a few lines of code, we are able to create a complete web application made of both back and frontend parts.
Summary
In this chapter, we started completing the decorations by adding a beautiful picture in the sidebar. The application should always work correctly but giving it a quite beautiful shape is always a good idea.
After decoration, we focused on the first voice of the menu: Text Analysis. Text Analysis is a quite complex section and in order to make it clear, good-looking, and well-performing, we decided to arrange our web application into different sections that cover different topics. The best solution to make this possible is to learn how to use columns and expanders. The Text Analysis section we created has two layers, one for Basic Functions and another for Advanced Features, and by using columns and expanders, we can manage both layers in a very effective and elegant way.
Columns allow us to place everything we want into pillars, while expanders allow us to expand or collapse anything we want to show or hide.
Having good-looking sections and well-arranged topics in our application is very important, but an extremely important point is having very well-performing code.
Code should run in a fast and smooth way, without taking a long time to load and show information on the screen. This is the reason why we also had a first look at caching in Streamlit.
In the next chapter, we are going to complete the two remaining voices of our menu: Translation and Sentiment Analysis.