
Tokens and lemmas
Tokens and lemmas are quite classical concepts of NLP. Tokens are the smallest units of a text and are usually identified with words. So, if we say I write code, we have three tokens: I, write, and code. Depending on the granularity level, things can get more complex because sometimes tokens can be identified with single letters. We don’t consider the letters, just the words. Please note that even with words, tokenization can be challenging; for example, in the sentence I’m writing code, we have many tokens – three or four. In the first case, I’m is a unique token, while in the second case, we can consider I’m as two words, with two different tokens.
There is no right or wrong approach but everything depends on the language and the use case to be considered. Lemmas are made of so-called plain text, so if we say code, coding, or coder, we can assume that for all these three words, the lemma is just code.
For Tokens&Lemmas, we can use spacy, a very powerful NLP package we imported in Chapter 4. Maybe you remember that, in Chapter 4, we also downloaded the English model used by spaCy (en_core_web_sm). Now we are using both the library and the model.
As we did for summarization, let’s write a function that takes care of tokens and lemmas. We can write, immediately after the summarization function, something like this:
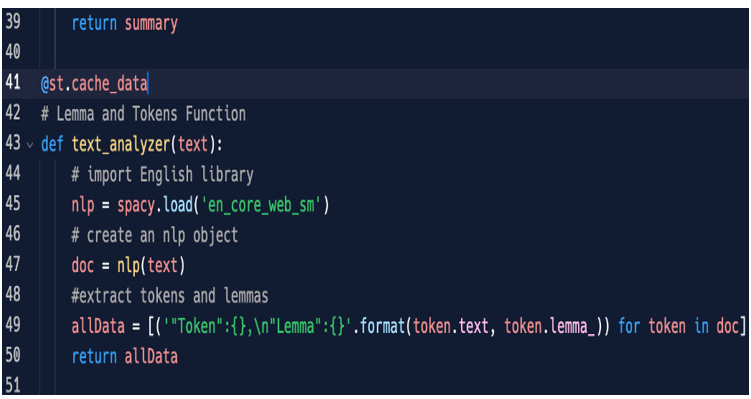
Figure 5.24: Lemmas and tokens function
First of all, we load in spaCy the English model, then create an nlp object (an object specific to the spacy library) from a text (doc=nlp(text)), and thanks to this object, we can extract tokens and lemmas (token.text and token.lemma_), saving them into a dictionary (a key:value data structure) named allData. At the very end, we return this allData variable.
Please note the strange @st.cache_data at the beginning of our function. It’s a decorator that tells Streamlit to save in a cache the data managed by this function, so unless the function’s input doesn’t change, any time we select the function, the response will be very fast.
Please check Streamlit’s official documentation about caching (https://docs.streamlit.io/library/advanced-features/caching) because it’s really something that can help a lot with response time:
Figure 5.25: Streamlit’s official documentation on caching
Our Tokens&Lemmas function is ready so we can use it inside our final expander.